Особенности
Мы постоянно работаем над тем, чтобы сделать наш API не только мощным, но и максимально удобным, надежным и выгодным для вас. В этом разделе мы собрали ключевые особенности, которые отличают HydraAI API.
Анонимность и конфиденциальность данных
Мы глубоко ценим вашу конфиденциальность и разработали HydraAI API с учетом высочайших стандартов анонимности и защиты данных. Наша цель — предоставить вам мощный инструмент, использование которого не ставит под угрозу вашу приватность.
Отсутствие логов запросов и ответов
Мы не храним историю ваших API запросов и ответов от нейросетей. Все данные, которые вы отправляете на генерацию (промты, сообщения, файлы), и результаты, которые вы получаете, обрабатываются "на лету" и не сохраняются на наших серверах. Это гарантирует, что содержание вашей работы остается исключительно вашим.
Анонимность на уровне аккаунта
Ваш API ключ не привязан ни к какому email, личному аккаунту или другим персональным данным. Процесс получения и пополнения ключа полностью анонимен, что исключает возможность связать вашу деятельность в API с вашей личностью.
Хранение API‑ключей – ваша ответственность
Все API‑ключи, полученные в нашей системе, полностью анонимны: они не привязаны к e‑mail, личному аккаунту или каким‑либо другим персональным данным. Поэтому мы не имеем возможности отследить, какие ключи были приобретены конкретным пользователем, и не можем предоставить вам список всех купленных ключей по запросу.
Что вам следует сделать:
- Сохраняйте ключи в надёжном месте – используйте менеджер паролей, зашифрованный файл или другое проверенное средство защиты.
- Не делитесь ключами публично – любой, кто получит доступ к вашему ключу, сможет использовать ваш баланс.
- Регулярно проверяйте активность – при появлении подозрительных запросов немедленно отзывайте соответствующий ключ и генерируйте новый.
Поскольку ключи не связаны с вашей личностью, восстановить их мы не сможем. Поэтому храните их аккуратно и ответственно.
Маршрутизация запросов для максимальной защиты
Чтобы минимизировать риск отслеживания, ваши запросы направляются к конечным провайдерам нейросетей через сложную систему прокси и с использованием разных аккаунтов. Эта многоуровневая маршрутизация делает практически невозможным отследить, что конкретный запрос исходит от конкретного пользователя нашего API, и предотвращает потенциальные утечки данных о том, что вы генерируете.
Хранение IP-адресов
Единственные данные, которые мы временно логируем — это IP-адреса, с которых поступают запросы. Это необходимо исключительно для технических целей: - Защита сервиса от DDoS-атак. - Предотвращение злоупотреблений и мошеннических действий.
Эти логи хранятся не более 3 суток, после чего полностью и безвозвратно удаляются.
Безопасное хранение изображений
Мы понимаем особую важность конфиденциальности при генерации изображений.
- Генерация по ссылке (
url): Изображения, сгенерированные в формате ссылки, хранятся на наших собственных S3-совместимых серверах. Мы не используем сторонние облачные хостинги, что обеспечивает полный контроль над данными и минимизирует риск утечек. Срок хранения таких изображений — всего 24 часа, после чего они автоматически и навсегда удаляются. - Генерация в формате
b64_json: Если вы выбираете этот формат ответа, сгенерированное изображение передается вам напрямую в виде строки Base64. В этом случае изображение не сохраняется нигде, даже на короткий срок, обеспечивая максимальный уровень приватности.
Универсальная поддержка инструментов (Function Calling)
Проблема: Многие модели или провайдеры нейросетей не поддерживают вызов инструментов (functions/tools), что ограничивает возможности автоматизации и создания сложных сценариев.
Наше решение: Мы реализовали универсальную поддержку tools для всех моделей в нашем API. Система интеллектуально интерпретирует ваш запрос с инструментами и преобразует его в понятный для любой модели формат. Ответ от модели, в свою очередь, десериализуется обратно в стандартную структуру tool_calls формата OpenAI.
Результат: Вы можете использовать стандартный синтаксис tools для всех моделей без исключения, даже если они изначально не поддерживают эту функцию. Это открывает новые возможности для интеграции и построения сложных логических цепочек.
Защита от некачественных ответов
Мы внедрили инновационные системы защиты, чтобы вы платили только за полезные результаты, экономя ваши деньги и время.
Zero Completion Token
Проблема: Иногда модели могут возвращать пустые, бессмысленные или состоящие только из пробелов ответы, за которые раньше приходилось платить.
Наше решение: Наша система автоматически анализирует каждый ответ от нейросети. Если ответ признан некачественным (пустым или бессмысленным), мы за наш счет отправляем запрос на повторную генерацию.
Результат: Вы гарантированно получаете только содержательные ответы и не тратите деньги на "пустышки".
Zero Generation Rate
Проблема: Генерация ответа могла "зависнуть" на неопределенное время из-за сбоев у провайдера или проблем с сетью, заставляя вас ждать и блокируя ваши процессы.
Наше решение: Мы отслеживаем время каждой генерации. Если запрос "зависает" и не выполняется в течение разумного времени, система автоматически прерывает его и возвращает вам деньги за несостоявшийся запрос.
Результат: Вы экономите время и деньги. Вы либо получаете ответ быстро, либо не платите за него вовсе.
Надежность и Мониторинг 24/7
Мы понимаем, насколько важна стабильность для ваших проектов. Поэтому мы создали продвинутую систему мониторинга, которая отслеживает состояние всех наших сервисов и нейросетей в реальном времени.
- Контроль доступности: Мы непрерывно проверяем работоспособность как API в целом, так и каждой отдельной модели.
- Отслеживание производительности: Мониторим время ответа и общую производительность, чтобы оперативно реагировать на замедления.
- Автоматические оповещения: Система мгновенно уведомляет нашу команду о любых аномалиях, позволяя решать проблемы до того, как они затронут вас.
- Публичный статус-пейдж: Вы всегда можете проверить текущее состояние наших систем в режиме реального времени.
Мы стремимся обеспечить аптайм не ниже 98%, чтобы ваш бизнес работал без перебоев.
Бесплатные запросы
Партнерская программа
Генерация изображений через чат
Данная функция позволяет вам создавать уникальные изображения, просто описывая их в текстовом сообщении. Ваш запрос отправляется через API-эндпоинт /chat/completions, но с выбором специальной модели, предназначенной для генерации изображений. Вся техническая работа по преобразованию вашего запроса в детализированный промт для нейросети и автоматическому подбору необходимых параметров генерации осуществляется нашей системой.
Важно
Функциональность генерации изображений через чат находится в тестовом режиме. Это означает, что могут возникать сбои в работе, а результаты могут варьироваться. Мы активно работаем над улучшением стабильности и качества генерации.
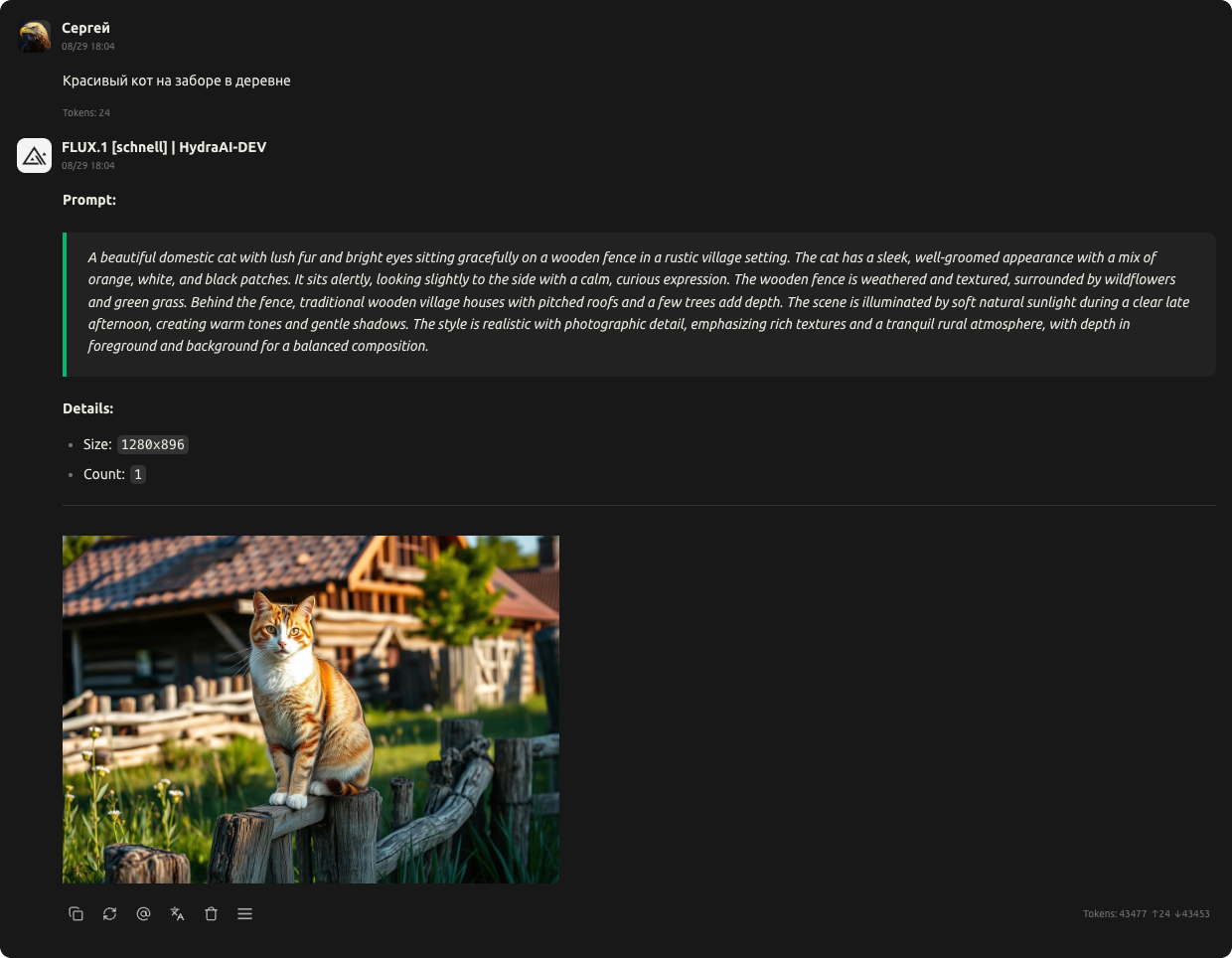
Как это работает:
- Просто опишите желаемое изображение: Отправьте в чат текстовое описание того, что вы хотите увидеть. Вы можете использовать любой язык.
- Интеллектуальная обработка запроса: Наша система анализирует ваш запрос, чтобы сгенерировать оптимальный промт для нейросети. Кроме того, система автоматически определяет подходящие параметры для создания изображения, такие как стиль, детализация и цветовая гамма. Если пользователь не указывает желаемый размер или количество изображений, система самостоятельно выберет поддерживаемый нейросетью размер, по умолчанию генерируя одно изображение.
- Генерация изображения: Нейросеть использует сформированный промт и параметры для создания одного или нескольких изображений.
- Получение результатов: Вы получите сгенерированное изображение (или изображения), а также информацию о процессе генерации, включая:
- Промт (Prompt): Текстовый запрос, который был отправлен нейросети.
- Детали:
- Размер (Size): Указанный размер сгенерированного изображения.
- Количество (Count): Сколько изображений было сгенерировано по вашему запросу.
Изображения передаются в формате Markdown (MD), где каждая картинка представлена как ссылка на данные в кодировке Base64. Начало данных изображения — data:image/jpeg;base64,.
Вот пример структуры ответа, который вы получите:
**Prompt:**
> [Текст промта, сгенерированного для нейросети]
**Details:**
- Size: [Размер изображения, например, 1024x1408]
- Count: [Количество сгенерированных изображений]
---


...
Важное примечание о стоимости
При использовании данной функции вы оплачиваете только стоимость непосредственно сгенерированных изображений, согласно текущим тарифам на генерацию изображений. Все дополнительные расходы, связанные с анализом вашего запроса, генерацией промтов и подбором параметров, в данный момент мы берем на себя.
Мы стремимся сделать этот процесс максимально удобным и интуитивно понятным. Пожалуйста, делитесь своими отзывами, чтобы помочь нам улучшить эту новую функцию!
Поиск в интернете через чат
Эта функция позволяет получать актуальную информацию из интернета, не покидая диалог с моделью. Ваш запрос отправляется через API-эндпоинт /chat/completions с дополнительным параметром web_search. Вся техническая работа — формирование запроса, парсинг сайтов и обработка контента — осуществляется нашей системой.
Важно
Функция работает только у поддерживаемых моделей (имеющих флаг "web_search": true). Проверить поддержку поиска для конкретной модели можно через API-эндпоинт /models.
Некоторые модели (например, с суффиксом -search) имеют встроенные механизмы поиска и не используют описанную ниже логику HydraAI.
Функциональность поиска находится в тестовом режиме. Возможны временные сбои или вариативность результатов. Мы активно работаем над стабилизацией.
Как активировать поиск
У вас есть два способа включить поиск:
-
Параметр
web_search(рекомендуемый): Добавьте этот параметр в тело JSON-запроса. Он поддерживает несколько режимов:-
trueили"links"— включает поиск и добавляет в ответ ссылки на использованные источники. -
"no-links"— включает поиск, но генерирует ответ в виде чистого текста без списка источников.
-
-
Суффикс модели: Добавьте суффикс к ID модели:
-
:search— равносильно"web_search": true(поиск с источниками). Пример:hydra-gpt:search. -
:search-no-links— равносильно"web_search": "no-links"(поиск без источников). Пример:hydra-gpt:search-no-links.
-
Как это работает
-
Анализ: Нейросеть анализирует ваше последнее сообщение и формирует оптимальный поисковый запрос.
-
Сбор данных: Система обращается к поисковикам, получает список релевантных сайтов и скачивает их содержимое.
-
Обработка: Специальный алгоритм очищает данные от рекламы и лишнего кода, выделяя только суть.
-
Генерация: Структурированная информация добавляется в контекст диалога, и целевая модель генерирует итоговый ответ на основе найденного.
Стоимость и использование токенов
Вы оплачиваете только входящие и исходящие токены основной модели.
В объекте ответа usage появляется специальное поле prompt_tokens_details.web_search_tokens. Оно показывает, сколько именно входных токенов было потрачено на добавленную информацию из интернета.
Важное примечание о стоимости
-
Объем входных токенов (
prompt_tokens) увеличится за счет добавления найденной информации. Количество этих дополнительных токенов указано вweb_search_tokens. -
Все промежуточные расходы (формирование поисковых запросов, парсинг сайтов, очистка данных) мы берем на себя. Вы за эти операции не платите.
Пример ответа
Обратите внимание на поле web_search_tokens внутри prompt_tokens_details:
{
"id": "wsc-id-869d7aa0-9f87-403c-aa4f-acd6e031df4c",
"object": "chat.completion",
"created": 1765102187,
"model": "gpt-4.1-nano",
"choices": [
{
"message": {
"role": "assistant",
"content": "Небо — это пространство над поверхностью земли..."
},
"finish_reason": "stop",
"index": 0
}
],
"usage": {
"prompt_tokens": 3361,
"prompt_tokens_details": {
"audio_tokens": 0,
"web_search_tokens": 3148
},
"completion_tokens": 289,
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0
},
"total_tokens": 3650,
"total_time": 32.237,
"cost_request": 0,
"free_request": true
}
}
Преимущества и ограничения
| Преимущества | Ограничения |
|---|---|
| Актуальность: Доступ к событиям в реальном времени. | Скорость: Время ответа увеличивается на 10-20 секунд из-за сбора данных. |
| Детальность: Данные берутся не просто из сниппетов, а из полного содержимого страниц. | Нет прямого парсинга: Нельзя отправить конкретную URL-ссылку для анализа, система ищет только по текстовому запросу. |
| Гибкость: Можно выбрать, нужны ли ссылки на источники в ответе. |
Примеры запросов
Ниже приведены примеры использования разных режимов поиска.
1. Поиск с источниками (стандартный)
Используйте true или "links", если вам нужно подтверждение фактов ссылками.
Пример запроса ("web_search": true)
{
"model": "hydra-gpt",
"web_search": true,
"messages": [
{
"role": "user",
"content": "Какие последние новости о миссии Artemis на Луну?"
}
]
}
2. Поиск без источников (чистый текст)
Используйте "no-links", если вам нужна сводка информации без загромождения текста URL-адресами.
Пример запроса ("web_search": "no-links")
{
"model": "hydra-gpt",
"web_search": "no-links",
"messages": [
{
"role": "user",
"content": "Кто выиграл последний чемпионат мира по футболу и с каким счетом?"
}
]
}
3. Активация через ID модели
Альтернативный способ включения поиска без передачи параметра web_search.
Пример запроса (через суффикс :search)
{
"model": "hydra-gpt:search",
"messages": [
{
"role": "user",
"content": "Курс биткоина на сегодня"
}
]
}
Пример запроса (через суффикс :search-no-links)
{
"model": "hydra-gpt:search-no-links",
"messages": [
{
"role": "user",
"content": "Краткая биография Илона Маска"
}
]
}